|
Tangloid.net
|
Enduce: Logic based data mining on continuous data
|
|
| |
| Download: |
Enduce v.0.92 | tgz, zip |
| C++ implementation with R binding |
|
| |
|
- Dinorms
Natural aggregation of dichotomic values.
|
- Contifiers
Continuous–data association quantifiers.
|
- Clustions
Notion clustering, based on contifiers.
|
| |
|
|
| The Enduce open-source
project is a data-mining approach based on fuzzy logic
that is applied to interval valued data.
It is the core of the Lingua
system - Fuzzy logic data-mining on gene expressions,
a bioinformatics targeted package for the R project.
Enduce is used as a framework for fuzzy logic driven libraries.
|
| |
| |
|
|
|
|
|
|
|
|
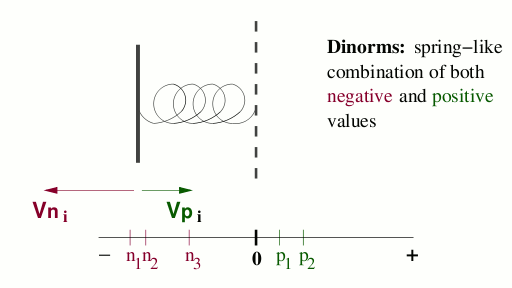
Dinorms are functions for aggregation of dichotomic values from the [-1, 1]
interval. The values are assumed to be supports for two
opposite situations. It can be e.g. reasons for cold vs. hot
situations, or underexpressed vs. overexpressed genes as
reasons for positive vs. negative advices for a treatment.
|
| |
|
The Dinorms functions are based on fuzzy logic connectives.
While it is known that we can not have functions natural
(i.e. continuous, commutative and associative functions)
for such dichotomic aggregations, it can be separated into
twofold process. First, negative and positive values are
aggregated separately in the natural way. Then the result
values are combined into a final aggregation (e.g. prognosis).
|
| |
|
The first step is done according to conorms - generalized
'or' functions. It leads into more firm judgements with
more support data. The second step is done according to
coimplicators - generalized form of functors complementary
to implications. They can be viewed as distance measures.
It has an advantage of possibility of multiple choices,
all of them can be combined naturally with at most one
nonzero result value.
|
|
|
|
|
|
|
| |
Contifiers view:
- a page (re)load gives a random count of case points with random locations
- drag the cases (circles)
to change their x,y-values inside the [0, 1]x[0, 1] square.
- click on the arrows to change directionality type of the computed associations: directed vs. mutual.
|
|
Contifiers are functors for aggregation of [0, 1]-interval valued pairs
when we look for relations (associations) between the pair items.
Particular value pairs are for data cases, i.e. individual experiments
or shopping carts.
The relations can be:
- directional, i.e. one being a witness for the second
- mutual, i.e. the pair items sharing some similarities
|
| |
|
The directional contifiers are for situations like 'when situation-A occurs then
situation-B frequently occurs too'. It can be e.g. for expression of a gene b
is triggered by a gene a. The mutual contifiers are for situations when the
relation is bidirectional. Contifiers are observational fuzzy-quantifiers from
a theoretical point of view.
|
| |
|
|
|
|
|
|
|
| |
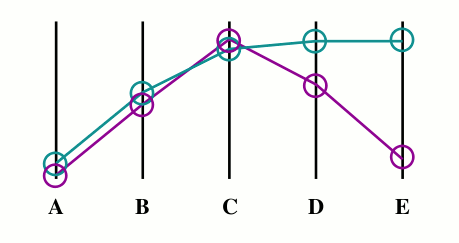
Clustions schema:
- both values zero-ish, neglected.
- similar, half-valued cases, half-counted pro.
- similar greatest values, the best.
- partially dissimilar values, worse.
- highly dissimilar values, the worst.
|
|
Clustions are for notion-wise clustering of [0, 1]-valued data,
with possible [-1, 1] interval being used as compressed pairs
of dichotomic data.
The clustering itself proceeds like k-means with the similarity
metrics based on Contifiers, especially the product ones.
It means that cases with zero-only values are neglected,
greater similar values count for, greater dissimilar values
count against.
|
| |
|
|
|
|
|
|
|
|
|